
Machine Learning, Data Science e Intelligenza Artificiale. Scopriamo cosa sono queste tecnologie, come funzionano e perché sono importanti.
Utilizziamo questo tipo di sistemi ogni giorno senza rendercene conto. Ma cos’è il machine learning?
Pensa ad esempio ai motori di ricerca.
L’algoritmo di Google che ti permette di ottenere in pochi decimi di secondi migliaia di risultati per la tua ricerca funziona proprio grazie al machine learning.
E lo sblocco tramite riconoscimento facciale degli smartphone?
Anche questa tecnologia funziona grazie all’apprendimento automatico.
Esperti da tutto il mondo studiano e ricercano nuove applicazioni dell’intelligenza artificiale nei vari ambiti lavorativi e quotidiani.
Alcune applicazioni del machine learning, come quelle in ambito medico, sono ad alto impatto sociale e permettono di diagnosticare tempestivamente le malattie più gravi.
In start2impact trovi un intero Percorso dedicato alla Data Science in cui è possibile studiare e mettersi alla prova con veri progetti pratici, così da diventare Data Scientist e lavorare nel campo dell’intelligenza artificiale.
In questo articolo scoprirai cos’è il machine learning, come funziona e in che modo può avere un impatto positivo sulla società.
La nascita dell’intelligenza artificiale

Facciamo un salto nel passato per scoprire la storia dell’intelligenza artificiale, la tecnologia che ci permette di studiare e analizzare grandi quantità di dati.
Nel 1956 sentiamo parlare per la prima volta di intelligenza artificiale, in inglese abbreviata come AI (Artificial Intelligence).
Negli anni ‘50 iniziava a svilupparsi il campo della computazione e cinque scienziati americani (vedi immagine sopra) tentarono un esperimento.
In due mesi un team di dieci esperti avrebbe dovuto creare una macchina in grado di simulare l’intelligenza umana e ogni aspetto dell’apprendimento.
Due mesi furono insufficienti e il loro progetto fallì, ma grazie alle loro intuizioni qualcosa di incredibile stava avendo inizio.
I primi tentativi di sviluppo dell’intelligenza artificiale
Grazie all’esperimento del 1956 possiamo distinguere due tipi di intelligenza artificiale: una generale e una ristretta.
L’AI generale contiene molteplici sottoinsiemi di AI ristretta, e sono: linguaggio naturale, percezione, ragionamento, pianificazione e conoscenza.
Si decise quindi di sviluppare l’AI a partire dallo studio dei sottoinsiemi specifici.
Negli anni ‘50 c’è stata la prima applicazione di AI ristretta nello sviluppo di macchine traduttrici inglese-russo.
Il Governo americano aveva bisogno di tradurre le conversazioni russe durante la Guerra Fredda e finanziò la ricerca.
A causa dell’assenza di dati e della scarsa potenza di calcolo dei computer del tempo, lo sviluppo di questa tecnologia non ebbe successo.
Nel 1966 gli Stati Uniti interruppero i fondi per la ricerca.
Si tornerà a parlare di AI soltanto nel 1980 con i “sistemi esperti” che avevano l’obiettivo di trasferire la conoscenza di un esperto (ad esempio, un medico) in un programma per computer.
Per realizzare un “sistema esperto” il programmatore faceva domande al dottore e trasformava la conversazione in righe di codice.
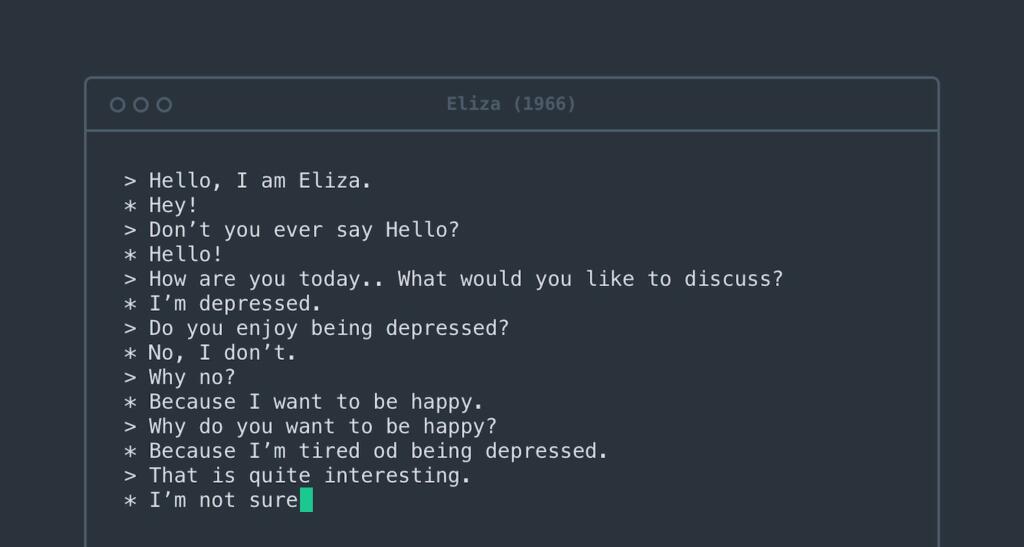
ELIZA è stato uno dei primi “sistemi esperti” e funziona come psicologo, puoi cercarlo su Google e parlare con lei!
Questi sistemi però erano in grado di rispondere solo ad alcune domande specifiche ed il costo per la realizzazione era eccessivo.
Fallito anche questo esperimento lo sviluppo dell’AI cadrà ancora una volta nello scetticismo.
Ora vediamo insieme il primo approccio con il machine learning!
Un nuovo approccio: il machine learning

Arthur Samuel, uno dei cinque scienziati che condusse il primo esperimento sull’AI nel 1956, definì il machine learning come:
“La scienza che dà ai computer l’abilità di imparare senza essere programmati esplicitamente.”
Se ancora ti stai chiedendo cos’è il machine learning, ecco a te una definizione più semplice: è un insieme di tecniche che permettono ai computer di imparare dai dati.
Nel 1997 un computer di IBM chiamato Deep Blue batte il campione mondiale di scacchi, Garry Kasparov.
Nel 2016 Alpha Go, computer di Google, riesce a battere il campione mondiale di Go, un gioco cinese con un totale di mosse possibili pari a 2,08×10170!
Per capirci, nel gioco degli scacchi le mosse possibili sono pari a 10123.
Gli ingredienti del machine learning sono:
- L’algoritmo che permette al computer di “apprendere”.
La comunità dell’AI è molto aperta e pubblica gratuitamente le scoperte e i nuovi algoritmi testati.
Inoltre, mette a disposizione diversi software gratuiti con cui lavorare all’AI. - I dati, necessari al computer per l’apprendimento.
Il machine learning impara dall’osservazione dei dati che utilizza come esempi per elaborare un modello in grado di fare previsioni future.
Alpha Go e Deep Blue hanno imparato a giocare grazie ai dati raccolti su milioni di partite dei rispettivi giochi da tavolo per cui sono stati programmati.
Oggi produciamo dati in continuazione ed i costi per lo storaggio, ovvero per il salvataggio su una memoria fisica, sono molto minori rispetto a quelli sostenuti 50 o 60 anni fa. - Potenza di calcolo per elaborare i dati e far funzionare gli algoritmi.
I computer odierni sono dodici volte più potenti di quelli utilizzati 10 anni fa, sono meno costosi e consumano molta meno energia.
Questi progressi sono stati determinanti per lo sviluppo dell’intelligenza artificiale.
Ora vediamo come funziona il machine learning e quali problemi ci permette di risolvere.
Come funziona il machine learning?

Ora che abbiamo capito cos’è il machine learning, capiamo insieme come funziona.
Prima di tutto, dobbiamo imparare alcune definizioni utili:
- Le features sono i valori che utilizzo come input per l’apprendimento;
- Le label sono i valori che voglio prevedere;
- I datapoint sono gli esempi, sotto forma di dati, che permettono al computer di imparare.
Quando forniamo all’algoritmo un datapoint, le features (input) e una label (output) parliamo di “supervised learning” (apprendimento supervisionato).
Permette di risolvere due tipi di problemi:
- Problemi di regressione: input e output sono continui e variano nel tempo.
Esempi di problemi di questo tipo sono le previsioni sull’andamento dei titoli in borsa. - Problemi di classificazione: input e output sono discreti.
Come nel riconoscimento facciale che è in grado di distinguere i volti umani, tutti diversi tra loro.
E se non avessimo nessuna label?
In questo caso parliamo di “unsupervised learning”.
L’apprendimento non supervisionato utilizza algoritmi di clustering, capaci di creare raggruppamenti di elementi a partire da una grande mole di dati.
Un algoritmo di clustering può essere utilizzato per definire il profilo di consumo con cui un’azienda energetica crea le offerte di mercato per gli utenti.
La capacità di generalizzare
Il punto di forza del machine learning è la generalizzazione, ovvero la capacità di imparare a risolvere un problema con qualsiasi tipo di dati.
Per sviluppare questa capacità i dati sono divisi in training set e test set.
I dati del training set servono per allenare il computer nella fase di apprendimento.
Il test set, invece, ci permette di valutare il corretto funzionamento dell’algoritmo nel momento in cui gli diamo in input dati diversi da quelli con cui ha imparato.
L’algoritmo migliore è quello in grado di generalizzare meglio e non quello che garantisce una precisione del 100% perché potrebbe trovarsi in difficoltà con un nuovo set di dati.
Eccoti un breve video in cui il nostro Super Coach Gian Gianluca Mauro ti spiega il processo di apprendimento del machine learning partendo dalle basi:
Applicazioni del machine learning

L’apprendimento automatico ci permette di trasformare in realtà cose che fino a pochi anni fa si potevano vedere soltanto nei film di fantascienza.
Vediamo alcune invenzioni realizzate grazie al machine learning:
1. Sistema di guida autonoma
Nel 2016 George Hotz, un giovane hacker americano (vedi foto sopra), ha costruito da autodidatta un sistema di guida autonoma nel garage di casa sua.
In un solo anno e con poche migliaia di euro è riuscito a realizzare qualcosa che negli anni ’50 non sono riusciti a fare in dieci anni e con milioni di finanziamenti.
Questo è stato possibile perché viviamo in un momento storico in cui la tecnologia, i computer e i software sono accessibili a tutti e molto più potenti degli strumenti che avevano anni fa.
La macchina di George è guidata da un sistema di intelligenza artificiale in grado di riconoscere la carreggiata ed evitare gli ostacoli.
Oggi Tesla è l’azienda leader nel settore automobilistico e produce autovetture autonome.
Con i dati raccolti dal GPS e altri sensori le auto imparano a riconoscere l’ambiente circostante e grazie agli algoritmi di machine learning riescono a muoversi verso la destinazione scelta.
2. Prevenzione di frodi
Il machine learning è utilizzato anche per la prevenzione di frodi (come la clonazione della carta di credito), dei furti di dati e identità.
Gli algoritmi imparano ad agire raccogliendo dati sulle abitudini di acquisto della gente e riescono ad identificare in tempo reale eventuali comportamenti anomali riconducibili ad attività fraudolente.
3. Previsioni e diagnosi in campo medico
In campo medico il machine learning è utilizzato per fare previsioni e diagnosi sui pazienti e individuare tempestivamente l’insorgere di malattie.
Gli algoritmi sono addestrati a partire dai dati raccolti su milioni di precedenti diagnosi, in questo modo imparano autonomamente a riconoscere i sintomi per individuare le diverse malattie.
A questo punto avrai capito che i dati sono l’elemento fondamentale per il corretto funzionamento di questa tecnologia, è importante quindi saper scegliere con cura i dati con cui addestrare gli algoritmi.
E come sono selezionati i dati?
Qui entra in gioco la Data Science.
Cos’è la Data Science?
Quando parliamo di Data Science facciamo riferimento all’insieme di tecniche con cui analizziamo e interpretiamo i dati per ricavarne informazioni utili.
Il Data Scientist è l’esperto di questa disciplina e attraverso un processo di analisi è in grado di individuare insight e previsioni sui trend.
Il processo di Data Science si divide in tre fasi:
- Analisi descrittiva: il Data Scientist lavora sui raw data, cioè sui dati “grezzi”.
I dati devono essere “puliti” per rimuovere quelli che hanno valori nulli o irregolari.
Se stiamo analizzando un dataset che contiene le date di nascita degli iscritti ad una piattaforma online e troviamo tra i valori persone nate nel 2030, è ovvio che quei dati andranno rimossi.
Questa fase si conclude con la realizzazione di un report e un grafico per rappresentare le informazioni ottenute dall’analisi. - Analisi predittiva: con i dati revisionati si realizzano previsioni future.
L’analisi predittiva permette di realizzare progetti ad alto impatto sociale.
Un modello di AI è stato addestrato per riconoscere le macerie dei palazzi crollati a partire da un dataset di foto aeree di palazzi distrutti.
Il modello è stato utilizzato per individuare le zone dove concentrare i soccorsi durante il terremoto che ha colpito Haiti. - Analisi prospettiva: si passa alla pratica, qui si prendono decisioni in base ai risultati ottenuti dalle due fasi precedenti.
Sapevi che la famosa serie tv La casa di carta ha avuto successo grazie a questo tipo analisi?
A partire dai dati raccolti sulle preferenze degli utenti, Netflix aveva capito che il genere di quella serie tv spagnola era molto apprezzato.
Con i risultati dell’analisi prospettiva Netflix ha deciso di acquistare i diritti de La casa di Carta per lanciarla nella sua piattaforma.
Come diventare Data Scientist

In start2impact crediamo che questa tecnologia possa migliorare la vita delle persone, così abbiamo creato il Percorso Data Science, ideato dal Super Coach Francesco Bagattini sulla base della sua pluriennale esperienza lavorativa nell’ambito Data Science.
Non sono richieste particolari competenze informatiche e di programmazione, nel Percorso Data Science impari tutto quello che c’è da sapere grazie ai contenuti che vengono costantemente aggiornati e ai Progetti Pratici con cui metterti subito alla prova.
Eccoti alcuni esempi di ciò che imparerai a fare:
- Realizzare un programma per la gestione dei file con il linguaggio di programmazione Python e NumPy;
- Rappresentare graficamente insight ottenuti a partire dai dati reali di un dataset pubblico del Washington Post sugli omicidi della polizia americana;
- Addestrare un modello di machine learning a ricavare informazioni rilevanti su come il consumo di alcool influisca sulle valutazioni scolastiche dei ragazzi.
I progetti vengono corretti dal nostro Coach entro una settimana dall’invio.
Grazie ai feedback personalizzati che spiegano esattamente come migliorare, i Membri della nostra Community possono esprimere il loro massimo potenziale.
In questo modo, acquisiscono le competenze richieste per diventare Data Scientist.
Alla fine del percorso, ci si potrà candidare per le Offerte di Lavoro da parte del nostro network di oltre 200 startup, grandi aziende, istituzioni e influencer partner.
In questo video Virginia e Gherardo, co-fondatori di start2impact, hanno intervistato il Super Coach Francesco Bagattini che ha spiegato com’è strutturato il corso per diventare Data Scientist:
Vogliamo avere un impatto positivo sulla vita delle persone e contribuire allo sviluppo della società per un futuro migliore
È per questo ogni giorno ci impegniamo per formare e ispirare migliaia di giovani.
La Community di start2impact è formata da giovani innovatori che vogliono intraprendere una Carriera nei Lavori del Futuro e utilizzare le competenze sviluppate per migliorare la vita delle persone.
Con un solo abbonamento hai accesso a 6 percorsi diversi, senza limiti: Data Science, Digital Marketing, UX/UI Design, Blockchain, Startup, Sviluppo Web e App.
Clicca qui per saperne di più!
Non perdere i prossimi articoli, segui start2impact su Telegram



